Tutorials
Consuming streaming data
Jump to on this page
Relevant products
Overview
PowerTrack, Volume (e.g. Decahose, Firehose), and Replay streams utilize Streaming HTTP protocol to deliver data through an open, streaming API connection. Rather than delivering data in batches through repeated requests by your client app, as might be expected from a REST API, a single connection is opened between your app and the API, with new results being sent through that connection whenever new matches occur. This results in a low-latency delivery mechanism that can support very high throughput.
The overall interaction between your app and Twitter’s API for these streams is described as follows:
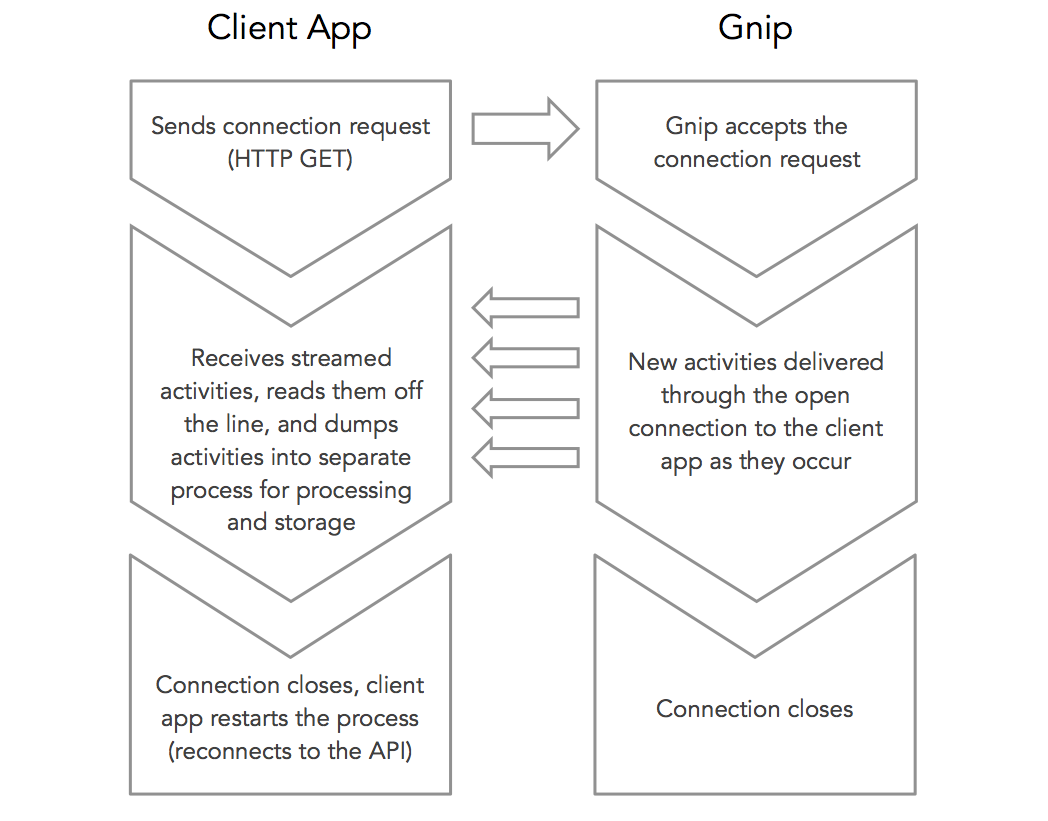
Step 1: Configure your stream
If you are using either the Decahose or Firehose, you don't need to configure your stream.
If you are using a PowerTrack or Replay stream, you need to set up some rules to define what content should be delivered through your stream. You can find out more about the PowerTrack rules syntax by reading our documentation on Premium Operators.
After you have configured your stream, you are ready to connect.
Step 2: Connect to the API
To open the data stream to have Tweets delivered, you need to send a connection request to the API. In the streaming model, this connection opens up the pipeline for data to be delivered to you as it happens, and will exist for an indefinite period of time. See the documentation for the specific APIs for information on establishing the connection.
Step 3: Consume the data as it’s delivered
Once the connection is established, the stream sends new Tweets through the open connection as they happen, and your client app should read the data off the line as it is received. Your client app will need to recognize and handle various types of messages, which are described in our documentation below.
Step 4: When disconnected, reconnect to the API
Inevitably, at some point the connection to the stream will close – a disconnection. With realtime streams, it is important to understand that you may be missing data any time you are disconnected from the stream. Whenever a disconnection occurs, your client app must restart the process by establishing a new connection.
Additionally, to ensure that you do not miss any data, you may need to utilize a Redundant Connection, Backfill, or a Replay stream to mitigate or recover data from disconnections from the stream.
Consuming the stream
After you establish the connection to your stream, you will begin receiving a stream of data. The body of the response consists of a series of carriage-return (\r\n) delimited JSON-endocded activities, system messages, and blank lines.
Your client should use the \r\n character to break activities apart as they are read in from the stream. Keep in mind that your app should not wait for the end of the “document” to begin processing the data. In effect, the document is never-ending, and your client will need to read the data off the line as it arrives.
JSON data
The individual data streamed by this API are JSON encoded, and fall into the following types:
- Tweets: Individual Tweet JSON objects
- Keep-alive Signals: Carriage returns to prevent your connection from timing out
- System messages: E.g. notification of a force disconnect. Note that the actual disconnection is accomplished via normal HTTP protocols, rather than through the message itself. In some cases the disconnect system message may not arrive, making it critical that you monitor the keep-alive signal (see below for more information).
Note that the individual fields of JSON objects are not ordered, and not all fields will be present in all circumstances. Similarly, separate activities are not delivered in sorted order, and duplicate messages may be encountered. Keep in mind that over time, new message types may be added and sent through the stream.
Thus, your client must tolerate:
- Fields appearing in any order
- Unexpected or missing fields
- Non-sorted Tweets
- Duplicate messages
- New arbitrary message types coming down the stream at any time
Tweets
JSON objects representing Tweets for the given data source are provided in the Twitter enriched native format. Please read our introduction to Tweet JSON documentation to learn more about this data format.
A Tweet will be contained on a single line and may contain linefeed \n characters, but will not contain carriage returns.
System messages
The Tweet stream may also contain system messages. Provided below is the basic format of these messages, along with some examples. Please note that the messages delivered could change, with new message being introduced. Client applications need to be tolerant of changing system message payloads.
Note that “sent” timestamps are in the YYYY-MM-DDTHH:mm:ssZZ format and in the UTC timezone.
Message format:
{"<message type>":{"message":"<the message>","sent":"<date time sent>"}}
System Message Types: There are currently 3 message types, each with a number of different messages. However, this is subject to change without notice.
- Info - “Replay Request Complete” is sent when a Replay stream request finishes. See below.
- Warn - E.g. if you’re connected to a PowerTrack stream which has zero rules.
- Error - These may be sent when certain issues occur, e.g. “Error while streaming data”, or for force disconnects.
Note that error messages indicating a force disconnect for a full buffer may never get to your client, if the backup which caused the force disconnect prevents it from getting through. Accordingly, your app should not depend on these messages to initiate a reconnect.
Examples:
{"error":{"message":"Forced Disconnect: Too many connections. (Allowed Connections = 2)","sent":"2017-01-11T18:12:52+00:00"}}
{"error":{"message":"Invalid date format for query parameter 'fromDate'. Expected format is 'yyyyMMddHHmm'. For example, '201701012315' for January 1st, 11:15 pm 2017 UTC.\n\n","sent":"2017-01-11T17:04:13+00:00"}}
{"error":{"message":"Force closing connection to because it reached the maximum allowed backup (buffer size is ).","sent":"2017-01-11T17:04:13+00:00"}}
Keep-alive signals
At least every 10 seconds, the stream will send a keep-alive signal, or heartbeat in the form of an \r\n carriage return through the open connection to prevent your client from timing out. Your client application should be tolerant of the \r\n characters in the stream.
If your client properly implements a read timeout on your HTTP library as described here, your app will be able to rely on the HTTP protocol and your HTTP library to throw an event if no data is read within this period, and you will not need to explicitly monitor for the \r\n character.
This event will typically be an exception being thrown or some other event depending on the HTTP library used. It is highly recommended to wrap your HTTP methods with error/event handlers to detect these timeouts. On timeout, your application should attempt to reconnect.
Gzip compression
Streams are delivered in compressed Gzip format. Your client will need to decompress the data as it’s read off the line. If you consume a low-volume stream, some libraries (e.g. Java’s GZIPInputStream or many Ruby stream consumers) handle decompression of incoming data poorly, and will need to be overridden in order to decompress the Tweets as they are received, without waiting for a set threshold of data to be received. As an example of this, see our Java code HERE.
Chunked encoding
Streaming API connections will be encoded using chunked transfer encoding, as indicated by the presence of a Transfer-Encoding: chunked HTTP header in the response. Because most HTTP libraries deal with chunked transfer encoding transparently, this document will assume that your code has access to the reassembled HTTP stream and does not have to deal with this encoding.
If this is not the case, note that Tweets and other streamed messages will not necessarily fall on HTTP chunk boundaries – be sure to use the delimiter defined above to determine activity boundaries when reassembling the stream.
Backup buffering
The stream will send data to you as fast as it arrives from the source firehose, which can result in high volumes in many cases. If Twitter’s system cannot write new data to the stream right away (for example if your client is not reading fast enough, or there is a network bottleneck, etc), it will buffer the content on its end to allow your client to catch up. However, when this buffer is full, a forced disconnect will be initiated to drop the connection, and the buffered Tweets will be dropped and not resent. See below for more details.
One way to identify times where your app is falling behind is to compare the timestamp of the Tweets being received with the current time, and track this over time.
Although stream backups cannot ever be completely eliminated due to potential latency and hiccups over the public internet, they can be largely eliminated through proper configuration of your app. To minimize the occurrence of backups:
- Ensure that your client is reading the stream fast enough. Typically you should not do any real processing work as you read the stream. Read the stream and hand the activity to another thread/process/data store to do your processing asynchronously.
- Ensure that your data center has inbound bandwidth sufficient to accomodate large sustained data volumes as well as significantly larger spikes (e.g. 3-4x normal volume). For filtered streams like PowerTrack, the volume and corresponding bandwidth required on your end are wholly dependent on what you are tracking, and how many Tweets those filters match.
A simple way to test the speed of your app is to connect to the stream using your app, while also connecting in parallel via a redundant connection using curl. The curl connection will provide insight into the type of performance that would occur with your app code taken out of the chain, and allowing you to eliminate variables as you debug.
Volume monitoring
Consider monitoring your stream data volumes for unexpected deviations. A data volume decrease may be symptomatic of a different issue than a stream disconnection. In such a situation, a stream would still be receiving the keep-alive signal and probably some new activity data. However, a significantly decreased number of Tweets should lead you to investigate whether there is anything causing the decrease in inbound data volume to your application or network, check api.twitterstat.us for any related notices.
To create such monitoring, you could track the number of new Tweets you expect to see in a set amount of time. If a stream’s data volume falls far enough below the specified threshold, and does not recover within a set period of time, then alerts and notifications should be initiated. You may also want to monitor for a large increase in data volume, particularly if you are in the process of modifying rules in a PowerTrack stream, or if an event occurs that produces a spike in Tweet activity.
Because each of our customers have very different expectations around what “normal” data volume should be for their streams, we do not have a general recommendation for a specific percentage decrease/increase or period of time. We recommend that each of our customers determine their own metrics to use for this type of monitoring.
Furthermore, for PowerTrack streams, in order to keep a close watch and tight control over the volume of data your app is pulling in, your app should monitor the volume being consumed on a rule-by-rule basis in realtime or near-realtime. Additionally, we encourage you to implement measures within your app that will alert your team if the volume passes a pre-set threshold, and to possibly introduce other measures such as automated deletion of rules that are bringing in too much data, or disconnecting from the stream completely in extreme circumstances. These steps will help prevent the “runaway volume” scenario that could result in large data bills.
Disconnections
For Twitter’s purposes, stream disconnections are grouped into two categories – client disconnections and forced disconnections.
Client disconnects
Client disconnects occur when your application independently terminates the connection to the data stream, whether because your code actively closes the connection, or where network settings or conditions terminate the connection.
Common issues in client code that can create this behavior include:
- Closing the connection, rather than allowing it to remain open indefinitely
- Timing out the connection even though data (activities, system messages, or keep-alive signals) are still being sent through the conneciton
- Decompressing the compressed stream using incorrect evaluation of chunk sizes
- Network or firewall restrictions in your infrastructure can close your connection to the data stream (e.g. firewall session limits) – be sure to check for anything along these lines that might sever existing connections from time to time.
- Again, using curl and comparing disconnect behavior can be a productive exercise. If your app is experiencing client-side disconnects, yet your curl connection persists, then your code needs some attention. If curl and your app disconnect at the same approximate time, then perhaps your network is timing out your connection.
Forced disconnects
Forced Disconnections occur when our system actively disconnects your app from the stream. There are 3 different types of forced disconnects.
- Full Buffer – your app is not reading the data fast enough, or a network bottleneck is slowing data flow.
- Too many connections – your app established too many simultaneous connections to the data stream. When this occurs, Twitter will wait 1 minute, and then disconnect the most recently established connection if the limit is still being exceeded.
- Server Maintenance – the Twitter team deployed a change or update to the system servers. This will be accompanied by a “Twitter is closing for operational reasons” message. These deploys happen on an approximately every-two-weeks cadence, and are announced at this status page.
Forced disconnects close your connection by sending a zero byte chunk in accordance with standard HTTP chunked-encoding practice. See Section 9 of this page for reference: http://www.httpwatch.com/httpgallery/chunked. Note that in the case of a full buffer, our app sends out the zero byte chunk, but your app may never receive it due to whatever is causing the data backup in the internet or within your app.
To account for this situation, be sure that your app is set to timeout/reconnect if it does not see any data (either a Tweet activity or our keep alive signal) for more than 30 seconds. They are registered as a “force disconnect” on your console/dashboard, in contrast to a “client disconnect” which is not initiated by Twitter’s servers.
To minimize forced disconnects for a full buffer, see Backup buffering above.
Reconnecting
When an established connection drops, attempt to reconnect immediately. If the initial reconnect attempt is unsuccessful, your client should continue attempting to reconnect using an exponential back-off pattern until it successfully reconnects.
Regardless of how your client gets disconnected, you should configure your app to reconnect immediately. If your first reconnection attempt is unsuccessful, we recommend that your app implement an exponential back-off pattern in subsequent reconnection attempts (e.g. wait 1 second, then 2 seconds, then 4, 8, 16, etc), with some reasonable upper limit. If this upper limit is reached, you should configure your client to notify your team so that you can investigate further.
Be sure that your app can handle all of the following scenarios:
- Connection is closed by something on your end (client disconnect)
- Connection is closed by Twitter with a zero-byte chunk (forced disconnect)
- Your app has received zero data through the connection – i.e. no new Tweets AND no keep-alive carriage return signals – for more than 30 seconds. Your app must allow the connection to time out in this situation – note that by default, some clients persistent connections can remain open even without new data unless your code tells it to close based on an absence of the above signals. Note that unlike the third scenario above, if you are still receiving the keep-alive signal, but no new data, your app should remain connected – there may be an issue on the Twitter side preventing data from being sent down the wire, or there may just not be any new activities that match your filters. Remaining connected as long as you are at least receiving the keep-alive signal ensures that you will receive new matching Tweets when they are received by Twitter. This is typically accomplished by setting the read timeout on your client to something beyond 30 seconds.
Missing data from disconnections
Any time you disconnect from the stream, you are potentially missing data that would be sent through at that time. However, Twitter provides multiple ways to mitigate these disconnects and recover data when they occur. See below for more information.
- Redundant Connections - Consume the stream from multiple servers to prevent missed data when one is disconnected.
- Backfill - Reconnect within 5 minutes and request a backfill of missed data.
- Replay - Recover data from within the last 5 days using a separate stream.
Special considerations for Replay streams
Replay allows enterprise customers to recover activities missed due to technical hiccups from a rolling window of historical data, and uses the Streaming API for data delivery. Full documentation for the Replay API can be found HERE.
However, your client must take into account the following requirements and special considerations when consuming data from a Replay stream.
Reconnections
Note that If you are disconnected from the stream during a Replay request, your app should not reconnect to the same URL used to initiate the request without altering the fromDate. Doing so will restart the request from the beginning and repeat the portion of time covered prior to disconnecting. Instead, upon being disconnected prior to the completion of a request, your client must adjust the fromDate and toDate in the URL to begin at the minute of the last activity you collected prior to the disconnection, to pick up from the same minute you left off, minimizing the amount of overlap.
Duplicates
We will not omit activities you may already have from a prior request, or your normal Power Track stream when delivering the results of a Replay request, and your app should deduplicate accordingly. Note, however, that for billing purposes, we deduplicate your activity counts across PowerTrack Replay requests that occur on the same day (based on UTC time) to ensure you are only billed once for each unique activity delivered via Replay. Activities delivered via the realtime Power Track stream are counted separately from those delivered via Replay.
Recovery
As mentioned above, PowerTrack and Volume Streams provide important features to help with realtime streams. See our documentation on Additional Streams, Redundant Connections, Replay Streams, and Backfill HERE.
Ready to build your solution?